

今日 Paper 联合抽取流式语音识别差异学习Skip-Thought向量等
目录
在序列标注模型中使用位置注意力进行抽取实体与重叠关系的联合抽取
将混合CTC/Attention方法嵌入到Transformer结构中实现在线端到端的流式语音识别架构
基于人工反向修正数据的差异学习
利用一种基于多属性邻近度的方法从可比较的新闻语料库中挖掘事件
Skip-Thought向量
在序列标注模型中使用位置注意力进行抽取实体与重叠关系的联合抽取
论文名称:Joint extraction of entities and overlapping relations using position-attentive sequence labeling
作者:Dai Dai / Xinyan Xiao / Yajuan Lyu / Shan Dou / Qiaoqiao She / Haifeng Wang
发表时间:2019/7/17
论文链接:https://paper.yanxishe.com/review/16071?from=leiphonecolumn_paperreview0416
推荐原因
本文设计了一种基于位置信息和上下文信息的注意力机制,同时将一个关系抽取任务拆成了n(n为句子的长度)个序列标注子任务,一个阶段即可将实体、关系等信息抽取出来。
本文发表时在两个数据集上达到了SOTA,并且对于跨度长的关系、重叠关系表现尤其好。
作者创造性的设计了一种标注方案(tag scheme),拆分关系抽取任务,更巧妙的是,设计了位置注意力机制,将多个序列标注任务放在同一个BLSTM模型中同时训练,让我对注意力机制的理解更深了一层。


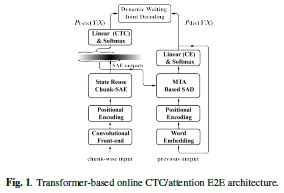
将混合CTC/Attention方法嵌入到Transformer结构中实现在线端到端的流式语音识别架构
论文名称:TRANSFORMER-BASED ONLINE CTC/ATTENTION END-TO-END SPEECH RECOGNITION ARCHITECTURE
作者:Haoran Miao /Gaofeng Cheng /Changfeng Gao /Pengyuan Zhang /Yonghong Yan
发表时间:2020/1/15
论文链接:https://paper.yanxishe.com/review/15406?from=leiphonecolumn_paperreview0416
推荐原因
为了有效地解决在线流式语音识别问题,作者先前提出了一种以BILSTM为基础结构的流式语音识别模型,本文是对上述的模型进行改进,一方面,采用transformer结构,并对其decoder的注意力模块进行改造,以提高识别CER分数。另一方面,对先前提出的将语音输入分割为chunks的方法进行改进,重用了部分重合的chunks的的hidden state,以减少识别耗时。
本文最终达到了23.66%的CER分数,并且仅有320ms的延时,同时,相对于离线的基线模型,CER分数仅损失了0.19%,大大提升了识别效果。
注:代码不是本文的实现代码,仅仅包含了本文改进的注意力机制部分。

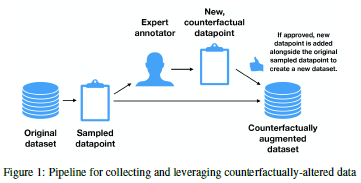
基于人工反向修正数据的差异学习
论文名称:LEARNING THE DIFFERENCE THAT MAKES A DIFFERENCE WITH COUNTERFACTUALLY-AUGMENTED DATA
作者:Divyansh Kaushik /Eduard Hovy /Zachary C. Lipton
发表时间:2019/9/6
论文链接:https://paper.yanxishe.com/review/15283?from=leiphonecolumn_paperreview0416
推荐原因
1 当前很多优秀的NLP模型,对数据中的虚假模式十分敏感,比如将文本分类模型中的关键词用同义词替代会使得模型效果大幅度降低,仅使用对话系统的问题或内容,在一些模型下,得到的结果与使用全部信息差别不大,等等。
2 针对以上问题,作者以一个情感分析和句子推理的数据集为基础,在众包平台上招募作者对数据集进行反向修正,在尽量不修改样本结构的情况下,让样本转变相反的标签,并以此为基础在一系列机器学习和深度学习的模型上进行训练,并且验证了作者认为反向修正的数据集能提高模型对于虚假模式的表现的想法。
3 使用高质量的人工标注样来让人类看起来傻乎乎的机器学习模型更加聪明,应该有不少人在做了,我没有做过相应的实验,但是觉得这样的做法很务实,其中用众包的形式来采集修正数据的想法也很有意思。值得一提的是,尽管使用了修正数据让模型能力提高了,但是对于基于bert预训练的模型提升效果有限,可能一方面由于bert模型从大量预料中学到了一些对抗虚假模式的知识,另一方面作者采取的实验是相对简单的句子级别的分类,期待作者关于对话系统的下一步工作。
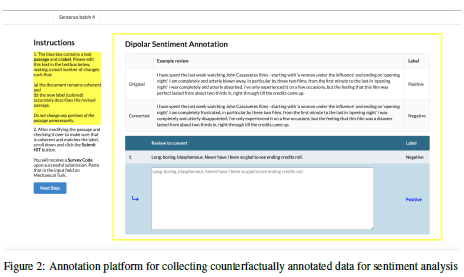
利用一种基于多属性邻近度的方法从可比较的新闻语料库中挖掘事件
论文名称:Mining News Events from Comparable News Corpora: A Multi-Attribute Proximity Network Modeling Approach
作者:Hyungsul Kim;Ahmed El-Kishky; Xiang Ren; Jiawei Han
发表时间:2019/11/14
论文链接:https://paper.yanxishe.com/review/15059?from=leiphonecolumn_paperreview0416
推荐原因
1.本文由韩家炜团队所发表,针对现有的新闻文本资料繁多,并且存在大量噪音、大量重叠内容的现状,提出了一种邻近度网络,利用其中大量重叠的内容,从时间、地点、相关人物、组织、以及事件之间的关联等属性的角度,定义了一种邻近度(Proximity )的方法,并以此为基础从中提取相关关键信息,并且得到新闻预料的事件,并以直观的图像的形式表达出来。
2.使用多属性的邻近度来替代文本的语义信息,比其他基于数据挖掘的事件提取方法更有效。同时,抽取事件信息的同时,对特定新闻事件,生成了信息丰富的事件图,事件的关键信息、事件之间的联系、联系的强弱,都被清楚的展示了出来。

Skip-Thought向量
论文名称:Skip-Thought Vectors
作者:RyanKiros /YukunZhu /RuslanSalakhutdinov
发表时间:2015/6/22
论文链接:https://paper.yanxishe.com/review/16077?from=leiphonecolumn_paperreview0416
推荐原因
skip-thought利用前后语句之间的关联性来学句子的embedding. 其句子的表征是用RNN来表示,模型先encode中间一个句子,然后用这个RNN的Output分别来decode前一个和后一个句子,直接类比于word2vec的Skip-gram的形式。



相关文章:
今日 Paper 分布式表示;基于元学习;县级数据集;GPS-NET等




