

用于形状精确三维感知图像合成的着色引导生成隐式模型 NeurIPS2021
编译 莓酊


神经体绘制
生成三维感知图像合成
从2D图像进行无监督的3D形状学习

3.1 神经辐射场的初步研究
 取三维坐标
取三维坐标 和观察方向
和观察方向 作为输入,并输出体积密
作为输入,并输出体积密 和颜色
和颜色 。为了在给定的相机姿势下渲染图像,通过沿其对应的相机光线
。为了在给定的相机姿势下渲染图像,通过沿其对应的相机光线 的体绘制获得图像的每个像素颜色C,如下所示:
的体绘制获得图像的每个像素颜色C,如下所示:
3.2着色引导生成隐式模型
 中采样的潜在编码z。其次,它不直接输出颜色c,而是输出可重新点亮的前余弦颜色项
中采样的潜在编码z。其次,它不直接输出颜色c,而是输出可重新点亮的前余弦颜色项 。
。 取坐标x、观察方向d和潜在方向编码z作为输入,并输出体积密度σ和前余弦颜色a。注意,这里σ独立于d,而a对d的依赖是可选的。为了获得相机光线
取坐标x、观察方向d和潜在方向编码z作为输入,并输出体积密度σ和前余弦颜色a。注意,这里σ独立于d,而a对d的依赖是可选的。为了获得相机光线 的颜色C,近界和远界
的颜色C,近界和远界 和
和 ,研究团队通过以下方式计算最终的前余弦颜色A:
,研究团队通过以下方式计算最终的前余弦颜色A:

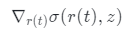 是体积密度σ相对于其输入坐标的导数,它自然捕捉局部法线方向,并可通过反向传播计算。然后通过Lambertian着色获得最终颜色C,如下所示:
是体积密度σ相对于其输入坐标的导数,它自然捕捉局部法线方向,并可通过反向传播计算。然后通过Lambertian着色获得最终颜色C,如下所示: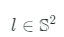 是照明方向,
是照明方向, 和
和 是环境系数和漫反射系数。
是环境系数和漫反射系数。 渲染像素颜色的过程。生成完整图像
渲染像素颜色的过程。生成完整图像 要求除潜在编码z外,还需对摄像姿势
要求除潜在编码z外,还需对摄像姿势 和照明条件μ进行采样,即
和照明条件μ进行采样,即 。
。 可以用俯仰角和偏航角来描述,并从先前的高斯分布或均匀分布
可以用俯仰角和偏航角来描述,并从先前的高斯分布或均匀分布 中采样,正如在以前的工作中所做的一样。在训练过程中随机采样相机姿势将激发学习的3D场景从不同角度看起来逼真。虽然这种多视图约束有利于学习有效的三维表示,但它通常不足以推断准确的三维对象形状。
中采样,正如在以前的工作中所做的一样。在训练过程中随机采样相机姿势将激发学习的3D场景从不同角度看起来逼真。虽然这种多视图约束有利于学习有效的三维表示,但它通常不足以推断准确的三维对象形状。 中随机采样照明条件μ来进一步引入多重照明约束。实际上,可以使用现有方法从数据集估算。在实验中,一个简单且手动调整的先验分布也可以产生合理结果。由于等式(4)中的漫反射项
中随机采样照明条件μ来进一步引入多重照明约束。实际上,可以使用现有方法从数据集估算。在实验中,一个简单且手动调整的先验分布也可以产生合理结果。由于等式(4)中的漫反射项 导致着色过程对法线方向敏感,该多重照明约束将使模型正则化,学习产生自然着色的更精确3D形状。
导致着色过程对法线方向敏感,该多重照明约束将使模型正则化,学习产生自然着色的更精确3D形状。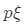 和
和 中采样潜在编码z、相机姿势
中采样潜在编码z、相机姿势 和照明条件μ来生成假图像
和照明条件μ来生成假图像 让l表示从数据分布pI中采样的真实图像。用
让l表示从数据分布pI中采样的真实图像。用 正则化的非饱和GAN损耗来训练ShadeGAN模型:
正则化的非饱和GAN损耗来训练ShadeGAN模型:
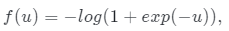 λ 控制正则化强度。
λ 控制正则化强度。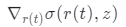 在物体表面附近趋于较大。
在物体表面附近趋于较大。3.3通过曲面跟踪实现高效体绘制


 和潜在编码z,可以渲染全深度贴图
和潜在编码z,可以渲染全深度贴图 。如上图(b)所示,使用表面跟踪网络
。如上图(b)所示,使用表面跟踪网络 模拟
模拟 ,这是一个以z,为输入并输出深度图的轻量级卷积神经网络。深度模拟损失为:
,这是一个以z,为输入并输出深度图的轻量级卷积神经网络。深度模拟损失为: 更好地捕捉表面边缘的感知损失。
更好地捕捉表面边缘的感知损失。 与发生器和鉴别器一起进行优化。每次在采样一个潜在编码z和一个相机姿势
与发生器和鉴别器一起进行优化。每次在采样一个潜在编码z和一个相机姿势 之后,可以得到深度贴图的初始猜测
之后,可以得到深度贴图的初始猜测 。
。 和远界
和远界 ,
, 是体积渲染的间隔,该间隔随着训练迭代i的增长而减小。
是体积渲染的间隔,该间隔随着训练迭代i的增长而减小。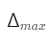 并减小到
并减小到 。像
。像 减少时,用于渲染m的点数也相应减少。与生成器相比,高效的曲面跟踪网络的计算成本是微乎其微的,因为前者只需要一次前向过程来渲染图像,而后者将被查询H × W × m 次。因此,m的减少将显著加快ShadeGAN的训练和推理速度。
减少时,用于渲染m的点数也相应减少。与生成器相比,高效的曲面跟踪网络的计算成本是微乎其微的,因为前者只需要一次前向过程来渲染图像,而后者将被查询H × W × m 次。因此,m的减少将显著加快ShadeGAN的训练和推理速度。
 的多元高斯分布作为先验。消融研究中还包括手工制作的先验分布。除非另有说明,否则在所有实验中,让前余弦颜色a取决于照明条件μ以及观察方向d。
的多元高斯分布作为先验。消融研究中还包括手工制作的先验分布。除非另有说明,否则在所有实验中,让前余弦颜色a取决于照明条件μ以及观察方向d。与基线进行比较


消融研究


光照感知图像合成
 ,以创建镜面反射高光效果。
,以创建镜面反射高光效果。
GAN反演

讨论
伯克利团队新研究:不用神经网络,也能快速生成优质动图
2022-01-08

NeurIPS 2021 旷视提出:空间集成 ——一种新颖的模型平滑机制
2021-11-20

英伟达CES发布会:“卡皇”RTX 3090 Ti初露脸,元宇宙工具开放个人免费版
2022-01-05





