摘要:Transformer这种具有强力全局编码能力的网络最近被应用于计算机视觉任务,例如ViT直接使用了一个Transformer来解决图像分类任务。为了处理二维图像数据,ViT简单地将图像分割,并映射成一个一维的序列。这种简单的分割使得图像固有的结构信息丢失,使得网络很难关注到重要的物体区域。为了解决这个问题,本文提出了一种迭代渐进采样策略来定位重要区域。具体来说,本文提出的progressive sampling模块,在每次迭代都会利用全局信息对采样位置进行更新,从而使得网络可以逐渐关注到感兴趣的信息。

论文链接:https://arxiv.org/pdf/2108.01684.pdf
作者:岳晓宇(博智感知交互研究中心);孙书洋(牛津大学);旷章辉(商汤科技);魏萌(清华大学);Philip Torr(牛津大学);张伟(商汤科技、上海交通大学清源研究院);林达华(香港中文大学、博智感知交互研究中心)。
在最近的研究中,具有强大全局编码能力的Transformer结构开始被用于诸如图像分类、目标检测等视觉任务。
我们知道Transformer的计算复杂度与输入序列长度的平方成正比,直接使用图像作为输入是不现实的。因而ViT使用了一种简单的方法对输入图像进行处理,如图一(a), ViT直接将图像进行规则的划分,每一部分图像(patch)直接映射成一个token。虽然这种简单的划分极大的减少了运算量并取得了很好的效果,但是它的缺点也是显而易见的,首先这种划分可能会将关键的部分划分到不同的patch,例如图一(a)中的猫头被强行分割成了不同的部分,其次这种划分是与图像的内容无关的,大部分patch的内容都是背景。
在本文中,我们提出了一种progressive sampling(PS)模块,来解决直接划分patch带来的问题。PS模块通过一种迭代的方式对图像进行采样,它是基于transformer的,我们直接将它用于ViT中,得到了PS-ViT。如图一(b),我们的PS模块对输入进行点采样,并在每次迭代中,为每个采样点预测一个偏移量,对采样位置进行更新,由此每个采样点可以逐步地逼近图像中的关键区域。
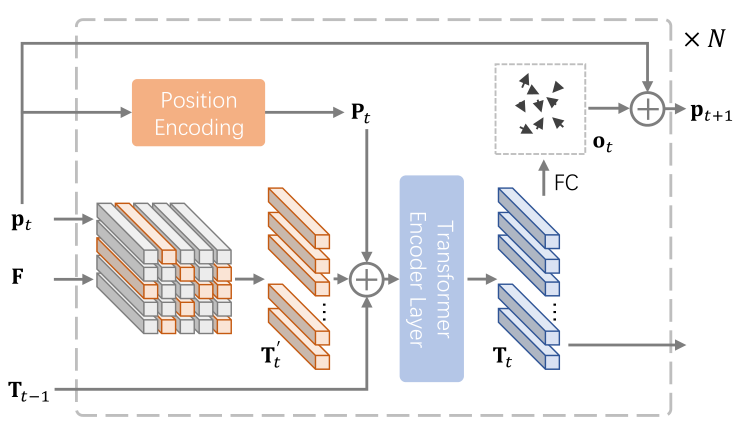
PS模块的结构如图二所示。整个网络中PS模块一共进行N次迭代,F是输入的图像特征图,pt是当前迭代次数t的采样位置,每个采样点在F中单独采样,由于采样点的坐标是非整数,因而我们采用了双线性插值来进行点采样。采样出的特征与采样点的位置编码和上一次迭代的输出进行相加,并将结果送入一层Transformer encoder,得到本次迭代的输出Tt。值得注意的是,由于我们的采样位置是非整数,因而这里不能用ViT中基于patch index的位置编码,我们直接使用了一层全连接层来得到采样点的位置编码。当前迭代的输出Tt经过一层全连接层,预测得到了ot为每个采样位置对应的偏移量,与pt相加得到了下一次迭代的采样位置。对于第一次迭代,初始的采样位置如图一(b)所示,为平均划分的每个patch的中心点。
PS-ViT的整体结构如图三所示。网络主要包括四个部分:1)特征提取模块;2)PS模块;3)ViT;4)分类模块。其中特征提取模块是用来生成特征图F的,这个模块是几层卷积,因而F中的每个像素可以对应到原图中的一个patch,对F中的点采样可以近似为对原图中的patch进行采样。ViT保持了原版设计,我们同样在输入上添加了一个classification token,但是这里并未使用位置编码,因为位置信息在PS模块中已经被添加了。
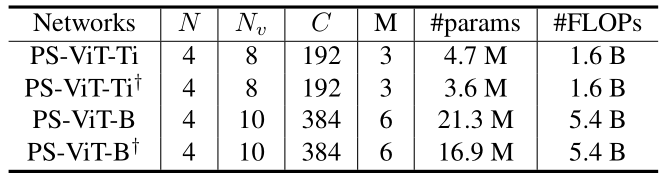
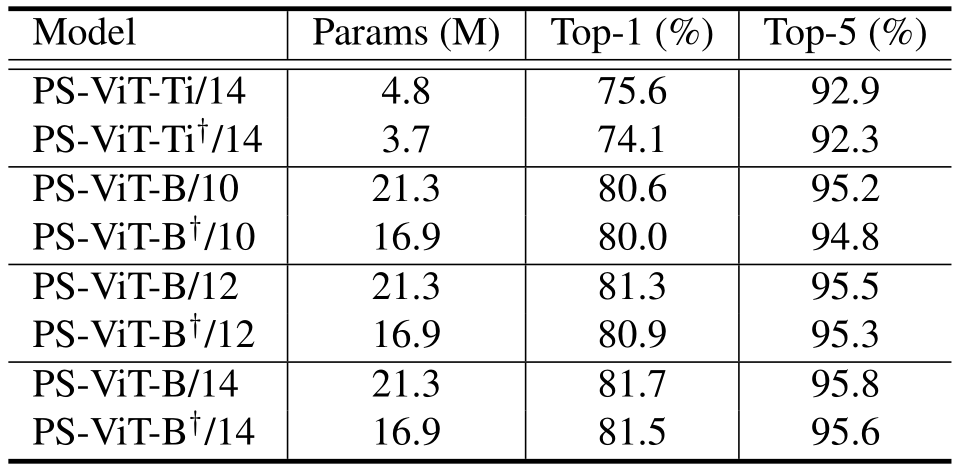
不同的PS-ViT配置如表一所示,N是PS模块迭代的次数,Nv是ViT的层数,我们保持两者相加等于一个固定数值来限制整个网络中transformer的层数。C是特征的维度,M是multi-head self-attention的head数量。考虑到PS模块中的每次迭代都具有相同的输入F,我们尝试在PS模块享参数,即不同的迭代中使用相同的encoder和全连接层,以此来减少网络的参数量,表一中的十字标识表示在PS模块享参数,可以看到大约25%的参数量可以被节省。我们在网络结构后添加数字表示横向和纵向采样点数量,例如PS-ViT-B/14表示使用了14*14个采样点。
PS-ViT在ImageNet上的效果如表二所示,PS-ViT-Ti/14与ResNet-18相比,在减少了6.9M参数量和0.2B FLOPs的同时获得了5.8%的top-1精度提升。PS-ViT-B/10与ResNet-50相比也有较大提升。与基于Transformer的方法相比,PS-ViT同样具有优势。PS-ViT-B/18取得了82.3%的top-1精度,在高于DeiT-B的同时,只需要21M参数量和8.8B FLOPs。
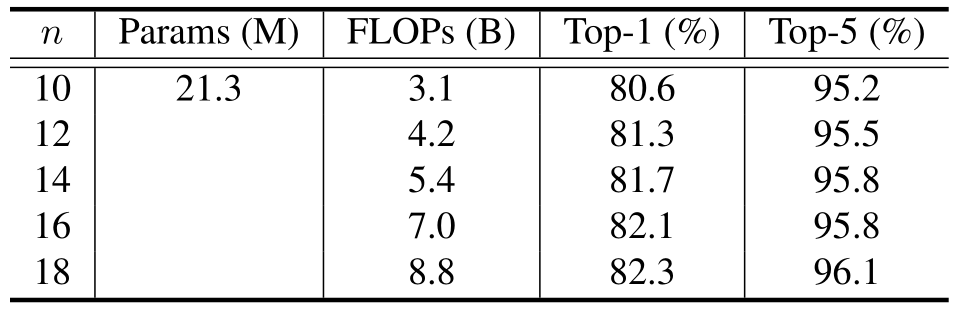
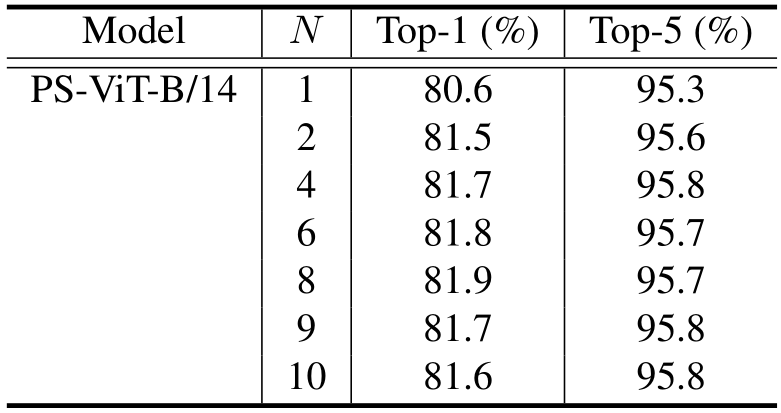
在本文中我们设计了实验来验证PS模块的有效性。在表三中我们验证了不同的采样点数量对效果的影响,在表四中验证了PS模块迭代次数的影响。
表三中的n表示沿着x方向和y方向分别的采样点数量,可以看到,随着采样点数量增加PS-ViT的效果和FLOPs都逐渐提高,当n>16时提高变得不明显,我们选择了14作为默认值。
表四中的N表示PS模块迭代次数,在这个实验中我们保持整个模型中总的transformer层数不变。当N=1时,表示只使用平均分布的初始点进行采样,并未对采样位置进行更新。可以看到随着迭代次数增加,PS-ViT效果逐渐提高。当N=8时效果最好,当N大于8时效果开始下降。由于我们保持整个网络的transformer层数为14,增加迭代次数会导致ViT模块层数减少,从而影响效果。
表五显示了PS模块不同的迭代享参数的结果。可以看到在PS模块享参数可以在效果只下降很少的情况下,极大的减少参数量。这种特性使得PS-ViT更适合在嵌入式设备中使用。
图四中我们对PS模块预测出的偏移量进行了可视化。图中每个箭头的起点为初始化的采样点,可以看到它们是平均分布的。箭头的终点是PS模块结束时,最后一次迭代的采样位置。可以看到采样位置大体上是向着图像中的前景部分移动,并最终收敛到关键部分(例如鸡头)附近。可视化说明了我们PS模块的有效性。
PS-ViT的代码已经开源: https://github.com/yuexy/PS-ViT ,欢迎大家一起交流。
雷峰约稿件,未经授权禁止转载。详情见转载须知。